
 20201124 DAY19 데이터 시각화 그래프 예제
20201124 DAY19 데이터 시각화 그래프 예제
plot() 시각화 그래프 출처: 《핸즈온 머신러닝》 2판(자료는 멘토님이 제공해주심) 원본 코드. 역시나 앞은 DAY15~18과 동일하고 오늘 코드는 67행부터 시작한다. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 import os import tarfile import urllib DOWNLOAD_ROOT = "https://raw.gi..
 20201104 riss 논문 크롤링 그 후: 명사 빈도 분석
20201104 riss 논문 크롤링 그 후: 명사 빈도 분석
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from konlpy.tag import Okt from konlpy.tag import Hannanum from collections import Counter from bs4 import BeautifulSoup import requests import re import pandas as pd import csv filename = "riss국내학술지.txt" f = open(filename, 'r', encoding='utf-8') news = f.read() okt = Okt() okt = Hannanum() noun = okt.nouns(news) count = Cou..
 20201124 DAY18 외부 데이터 가져오기 예제
20201124 DAY18 외부 데이터 가져오기 예제
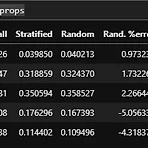
train_test_split() 훈련 데이터와 테스트 데이터를 분리한다. income_cat_proportions() 상대적인 비율 값을 가져오기 위해 정의(def)하는 사용자 함수. 출처: 《핸즈온 머신러닝》 2판(자료는 멘토님이 제공해주심) 원본 코드. 역시나 앞은 DAY15~17과 동일하고 오늘 코드는 43행부터 시작한다. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 import os import tarfile i..
 20201123 DAY17 OECD 데이터 표현 예제
20201123 DAY17 OECD 데이터 표현 예제
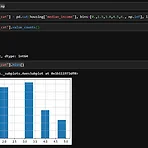
pd.cut() 연속형 변수를 범주형 변수(bins)로 변경하는 함수이다. value_counts() 범주형 변수의 유형값에 대한 개수를 구한다. hist() 히스토그램을 표시한다. 출처: 《핸즈온 머신러닝》 2판(자료는 멘토님이 제공해주심) 원본 코드. 34행까지는 DAY 16과 동일하다. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import os import tarfile import urllib DOWNLOAD_ROOT = "https://raw.githubusercontent.com/rickiepark/handson-ml2/mast..
 20201120 DAY16 외부데이터 가져오기
20201120 DAY16 외부데이터 가져오기
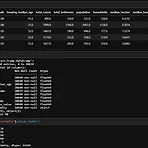
pd.read_csv() csv 파일을 읽어들인다. head() 첫 5개 행을 반환한다(이때까진 보통 확인용으로 많이 썼던 함수). info() 데이터프레임에 대한 간결한 요약을 출력한다. 로우/컬럼의 갯수나 데이터 타입 같은 걸 알려준다. value_counts() 한국어로는 범주형 특성의 각 유형값의 개수를 반환한다... 고 되어 있는데 return a series containing counts of unique values라고 하면 유일한 값의 수를 가지는 집합을 반환한다는 뜻이니까, 데이터가 만약 AAABBCC 이렇게 있으면 A 3, B 2, C 1 이런 식으로 출력해 주는 것 같다. 추가: 이게↑ 정확히 무슨 뜻인가 하고 구글링을 하다 보니 unique() 라는 함수로 유일한 값을 찾을 수 있..
 20201119 DAY15 외부데이터 가져오기
20201119 DAY15 외부데이터 가져오기
os.path.join() 경로명을 생성하는 함수 urllib.request.urlretrieve() 네트워크를 통해 해당 url의 파일을 로컬 경로로 다운로드한다. tarfile.open() 경로명 name에 대한 tarfile 객체를 반환한다. extractall() tarfile 객체에 대해 압축을 해제한다. 출처: 《핸즈온 머신러닝》 2판(자료는 멘토님이 제공해주심) 원본 코드 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import os import tarfile import urllib DOWNLOAD_ROOT = "https://raw.githubusercontent.com/rickiepark/handson-ml2/master/" HOUSING_PATH =..
LinearRegression() 회귀 모형 함수이다. sklearn.linear_model.Lasso with l1 regularization sklearn.linear_model.Ridge with l2 regularization sklearn.linear_model.ElasticNet with both l1 and l2 fit(X, y, sample_weight=None) Traing data의 X, Target values의 y로 모델을 훈련한다. 출처: 《핸즈온 머신러닝》 2판(자료는 멘토님이 제공해주심) 어제 한 코드(applecider1002.tistory.com/29)에서 이어진다. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ..
 20201117 DAY13 OECD 데이터 시각화
20201117 DAY13 OECD 데이터 시각화
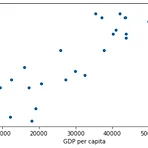
OECD에서 배포한 life satisfaction 데이터와 1인당 GDP를 합치는 함수를 정의하고, 데이터를 시각화하는 코드이다. oecd_bli_2015.csv와 gdp_per_capita.csv는 구글링하면 찾을 수 있다. 출처: 《핸즈온 머신러닝》 2판(자료는 멘토님이 제공해주심) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def prepare_country_stats(oecd_bli, gdp_per_capita): oecd_bli = oecd_bli[oecd_bli["INEQUALITY"]=="TOT"] oecd_bli = oecd_bli.pivot(index="Country", columns="Indicator", va..
- Total
- Today
- Yesterday
- data annotation
- googlecolab
- 이력서
- 데이터준전문가
- Kaggle
- 빅분기합격
- ADsP
- 이자포스터디
- 빅분기후기
- Til
- 인공지능
- 깃허브
- github
- 커리어코칭
- 데이터분석
- todayIlearned
- 자격증
- 빅데이터
- Notion2Tistory
- 취업준비
- 코테공부
- 코드스테이츠
- 데이터준전문가합격후기
- 자버
- ai부트캠프
- 데이터과학
- 개발자포트폴리오
- 빅분기
- 빅데이터분석기사
- ADsP합격후기
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |