
티스토리 뷰
train_test_split() 훈련 데이터와 테스트 데이터를 분리한다.
income_cat_proportions() 상대적인 비율 값을 가져오기 위해 정의(def)하는 사용자 함수.
출처: 《핸즈온 머신러닝》 2판(자료는 멘토님이 제공해주심)
원본 코드. 역시나 앞은 DAY15~17과 동일하고 오늘 코드는 43행부터 시작한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
import os
import tarfile
import urllib
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/rickiepark/handson-ml2/master/"
HOUSING_PATH = os.path.join("datasets", "housing")
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
def fetch_housing_data(housing_url = HOUSING_URL, housing_path = HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
fetch_housing_data()
import pandas as pd
def load_housing_data(housing_path = HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
housing=load_housing_data()
housing.head()
housing.info()
housing["ocean_proximity"].value_counts()
housing.describe()
import numpy as np
housing["income_cat"] = pd.cut(housing["median_income"], bins=[0.,1.5,3.0,4.5,6., np.inf], labels=[1, 2, 3, 4, 5])
housing["income_cat"].value_counts()
housing["income_cat"].hist()
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import train_test_split
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[train_index]
def income_cat_proportions(data):
return data["income_cat"].value_counts() / len(data)
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
compare_props = pd.DataFrame({
"Overall": income_cat_proportions(housing),
"Stratified": income_cat_proportions(strat_test_set),
"Random": income_cat_proportions(test_set),
}).sort_index()
compare_props["Rand. %error"] = 100 * compare_props["Random"] / compare_props["Overall"] - 100
compare_props["Strat. %error"] = 100 * compare_props["Stratified"] / compare_props["Overall"] - 100
|
cs |
train_set과 test_set을 정의하기 위해서 사이킷런에서 StratifiedShuffleSplit과 train_test_split을 불러와야 한다.
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import train_test_split그 다음 split을 다음과 같이 정의해준다.
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for문은 뭔지 잘 모르겠는데 일단 구글링해서 긁어왔음. 차차 코드 뜯어보려고 함.
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[train_index]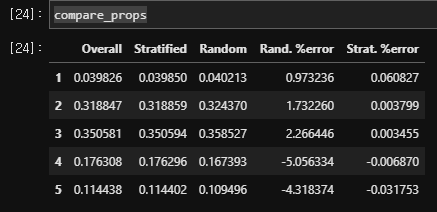
'공부 > Python' 카테고리의 다른 글
| 20201126 DAY20 scatter matrix (0) | 2020.11.26 |
|---|---|
| 20201124 DAY19 데이터 시각화 그래프 예제 (0) | 2020.11.25 |
| 20201123 DAY17 OECD 데이터 표현 예제 (0) | 2020.11.23 |
| 20201120 DAY16 외부데이터 가져오기 (0) | 2020.11.20 |
| 20201119 DAY15 외부데이터 가져오기 (0) | 2020.11.19 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 코드스테이츠
- 빅데이터분석기사
- 커리어코칭
- ADsP
- 코테공부
- data annotation
- 개발자포트폴리오
- 깃허브
- ADsP합격후기
- 취업준비
- 이자포스터디
- 데이터준전문가합격후기
- 빅분기후기
- Notion2Tistory
- todayIlearned
- 빅분기합격
- 데이터준전문가
- ai부트캠프
- 자버
- 이력서
- 자격증
- 데이터분석
- 빅데이터
- Til
- 데이터과학
- Kaggle
- 빅분기
- 인공지능
- googlecolab
- github
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함