
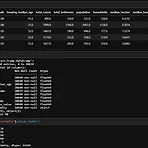
 20201120 DAY16 외부데이터 가져오기
20201120 DAY16 외부데이터 가져오기
pd.read_csv() csv 파일을 읽어들인다. head() 첫 5개 행을 반환한다(이때까진 보통 확인용으로 많이 썼던 함수). info() 데이터프레임에 대한 간결한 요약을 출력한다. 로우/컬럼의 갯수나 데이터 타입 같은 걸 알려준다. value_counts() 한국어로는 범주형 특성의 각 유형값의 개수를 반환한다... 고 되어 있는데 return a series containing counts of unique values라고 하면 유일한 값의 수를 가지는 집합을 반환한다는 뜻이니까, 데이터가 만약 AAABBCC 이렇게 있으면 A 3, B 2, C 1 이런 식으로 출력해 주는 것 같다. 추가: 이게↑ 정확히 무슨 뜻인가 하고 구글링을 하다 보니 unique() 라는 함수로 유일한 값을 찾을 수 있..
 20201119 DAY15 외부데이터 가져오기
20201119 DAY15 외부데이터 가져오기
os.path.join() 경로명을 생성하는 함수 urllib.request.urlretrieve() 네트워크를 통해 해당 url의 파일을 로컬 경로로 다운로드한다. tarfile.open() 경로명 name에 대한 tarfile 객체를 반환한다. extractall() tarfile 객체에 대해 압축을 해제한다. 출처: 《핸즈온 머신러닝》 2판(자료는 멘토님이 제공해주심) 원본 코드 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import os import tarfile import urllib DOWNLOAD_ROOT = "https://raw.githubusercontent.com/rickiepark/handson-ml2/master/" HOUSING_PATH =..
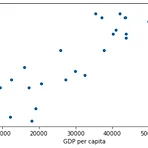 20201117 DAY13 OECD 데이터 시각화
20201117 DAY13 OECD 데이터 시각화
OECD에서 배포한 life satisfaction 데이터와 1인당 GDP를 합치는 함수를 정의하고, 데이터를 시각화하는 코드이다. oecd_bli_2015.csv와 gdp_per_capita.csv는 구글링하면 찾을 수 있다. 출처: 《핸즈온 머신러닝》 2판(자료는 멘토님이 제공해주심) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def prepare_country_stats(oecd_bli, gdp_per_capita): oecd_bli = oecd_bli[oecd_bli["INEQUALITY"]=="TOT"] oecd_bli = oecd_bli.pivot(index="Country", columns="Indicator", va..
 20201116 DAY12 네트워크 객체 다운로드 및 저장
20201116 DAY12 네트워크 객체 다운로드 및 저장
os.path.join(): 하나 이상의 경로를 결합한다. os.makedirs(): 디렉토리를 생성한다. exist_ok = True이면 폴더가 존재하지 않을 경우 생성하고 존재할 경우에는 아무것도 하지 않음(해봤는데 False로 놓아도 큰 차이가 없는 것 같다. 뭐지?). urlretrieve(): url로 표시된 네트워크 객체, 즉 url 주소에 해당하는 문서를 로컬 파일로 저장한다. 코드 1 2 3 4 5 6 7 8 9 10 11 import os datapath = os.path.join("datasets", "lifesat", "") import urllib.request DOWNLOAD_ROOT = "https://raw.githubusercontent.com/rickiepark/handso..
파이썬에서의 벡터의 표현과 전치를 알아봤다. 마침 이번 학기에 선형대수학을 수강하고 있어서 약간 반가움(?). 원래 코드 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import numpy as np a = np.array([2, 1]) print(a) type(a) c = np.array([[1, 2], [3, 4]]) print(c) d = np.array([[1], [2]]) print(d) print(d. T) cs 8행과 11행에서 바깥쪽 []를 하나 빼먹으면 다음과 같은 오류가 난다. 이 오류에 대해서 이해하고 싶은데 좀 이따 찾아봐야겠다. --------------------------------------------------------------------------- Ty..
 20201111 DAY09 3차원 그래프 그리기
20201111 DAY09 3차원 그래프 그리기
함수의 표면 표시: surface 함수 원래 코드 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D xn = 9 x0 = np.linspace(-2, 2, xn) x1 = np.linspace(-2, 2, xn) xx0, xx1 = np.meshgrid(x0, x1) plt.figure(figsize=(5, 3.5)) ax = plt.subplot(1, 1, 1, projection='3d') ax.plot_surface(xx0, xx1, y, rstride=1, cstride=1, alpha=0.5, color='co..
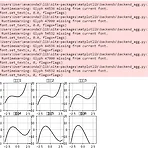 20201109 DAY07 그래프 여러 개 보여주기
20201109 DAY07 그래프 여러 개 보여주기
6개 그래프 그리기(plt.subplot 함수) (출처: 《파이썬으로 배우는 머신러닝의 교과서》, 코드는 멘토님이 제공) 원래 코드 import numpy as np import matplotlib.pyplot as plt #x를 정의 x = np.linspace(-3, 3, 100) #x를 -3에서 3까지 100개 분할 def f2(x, w): return (x - w) * x * (x + 2) #함수 정의 plt.figure(figsize=(10, 3)) # (A) figure 지정 plt.subplots_adjust(wspace=0.5, hspace=0.5) # (B) 그래프 간격 지정 for i in range(6): #그래프 묘사의 위치 지정 plt.subplot(2, 3, i+1) #subpl..
- Total
- Today
- Yesterday
- 빅데이터
- Notion2Tistory
- Kaggle
- 개발자포트폴리오
- 커리어코칭
- 데이터분석
- github
- 자격증
- 빅분기
- 이자포스터디
- todayIlearned
- ai부트캠프
- 코드스테이츠
- 데이터과학
- 인공지능
- 깃허브
- 빅분기후기
- 이력서
- ADsP
- 데이터준전문가합격후기
- 데이터준전문가
- 빅분기합격
- 자버
- ADsP합격후기
- 취업준비
- googlecolab
- Til
- 코테공부
- 빅데이터분석기사
- data annotation
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |