
티스토리 뷰
제목대로 yolov5를 처음! 써보았다. DS를 공부하는 사람으로서는 매우 뒤늦었지만… 늦게라도 기록해두고 싶어서 정리해 본다. 우선 전체 코드는 여기에 공유. 처음 해보는 분들께 참고가 되길 바란다.
이번에는 내가 직접 데이터세트를 만들지는 않았고, Roboflow에서 제공하는 프리 데이터 세트를 그대로 활용했다.
특히 Roboflow는 yolov5가 요구하는 형태로 데이터세트를 제공하기 때문에, 별도로 yaml 파일을 세팅하는 번거로움에서 벗어날 수 있다는 장점이 있다(다른 분들의 기록을 보니 이게 정말정말 귀찮은 과정이더라…).
Roboflow에서 내가 다운로드한 데이터는 Dice Dataset으로, 따로 train, test, valid 세트가 나뉘어져 있지 않아서 수동으로 나누어야 했다. 그리고 yaml 파일에 각 세트의 상대 경로도 지정되어 있지 않았다.
따라서, yolov5를 공식 레포지토리에서 클론해오고 환경 세팅만 제대로 하고 나면
- ① Roboflow API 연결하기
- ② 데이터 세트 형식 가공하기
이 두 가지 문제가 최우선으로 해결되어야 하는 셈이다.

API 키를 받고 데이터세트로 돌아가서 내가 원하는 양식으로 데이터를 받을 수 있다.
zip파일 다운로드뿐만 아니라 colab이나 jupyter에서 바로 사용 가능한 코드 형태로 제공해주기도 한다.
그리고 이 데이터 세트에 대한 yaml 파일이 없으면 yolov5를 돌릴 수 없으므로 yaml에 경로를 추가해주자. 사전에 데이터 세트가 모두 동일한 확장자인지, 분류될 클래스는 총 몇 개인지 정도의 기본적인 정보는 Roboflow에서 알려준다.
내가 다룰 데이터세트는 크기가 718로 많지 않다고 판단하여 따로 test set를 만들지 않았다.
# -------- 경로 지정
import os
root_dir = "/content/yolov5/data/Dice-2"
img_dir = os.path.join(root_dir, "images")
label_dir = os.path.join(root_dir,"labels")
# -------- 데이터세트를 train/valid로 분리하고 각각의 txt 만들기
import glob
data = glob.glob(os.path.join('/content/yolov5/data/Dice-2/export/images/',"*.jpg"))
train = data[:574] # 718 * 0.8
valid = data[574:]
# train.txt
with open(os.path.join(root_dir, "train.txt"), 'w') as f:
f.write('\n'.join(train) + '\n')
# valid.txt
with open(os.path.join(root_dir, "valid.txt"), 'w') as f:
f.write('\n'.join(valid) + '\n')
# -------- yaml에 경로 지정하기
import yaml
yaml_data = {"names":['1', '2', '3', '4', '5', '6'], # 클래스 이름
"nc":6, # 클래스 수
"path":root_dir, # root 경로
"train":os.path.join(root_dir, "train.txt"), # train.txt 경로
"val":os.path.join(root_dir, "valid.txt"), # valid.txt 경로
}
with open(os.path.join(root_dir, "data.yaml"), "w") as f:
yaml.dump(yaml_data, f)
아래는 훈련 py, 검출 py를 순서대로 돌린 코드이다. 최소한의 옵션만 설정했다.
- train: 이미지 리사이징 크기 / batch size는 8 / epoch는 200회 / data yaml이 위치한 경로 / 어느 GPU를 쓰는지 / 가중치 pt 경로(※여기서는 COCO로 훈련한 기본 yolov5s.pt를 사용) / 결괏값을 저장할 폴더 이름
- detect: 위에서 생성한 가중치 pt 파일의 경로 / 데이터 크기 / confidence score / img 폴더 경로
이때 train.py를 무사히 잘 돌리면 최적의 가중치를 best.pt라는 파일로 뽑아주는데, 이것이 있어야 detect를 할 수 있다.
내가 초반에 했던 실수처럼 train이 돌아가지 않으면 best가 나오지 않고, 다른 pt 파일을 넣어보면 주사위의 눈이 아니라 사람 손가락 같은 걸 검출해서 알려준다. 다른 세트로 훈련한 가중치를 썼으니 당연한 일임^^;;;
즉 best.pt가 생성되어야 모델이 제대로 훈련했다는 뜻이니 착각하지 말자.
python train.py --img 640 --batch 8 --epochs 200 --data Dice-2/data.yaml --device 0 --weights yolov5s.pt --name final --cache
python detect.py --weights /content/yolov5/runs/train/final/weights/best.pt --img 718 --conf 0.25 --source /content/yolov5/data/Dice-2/export/images
검출까지 끝낸 다음 yolov5 폴더 안의 runs 폴더를 열어보면 뭐가 많이 생겨 있다.
하나하나 눌러보면 다음과 같은 이미지들인데 모델이 잘 학습했는지를 알려주는 것이다.
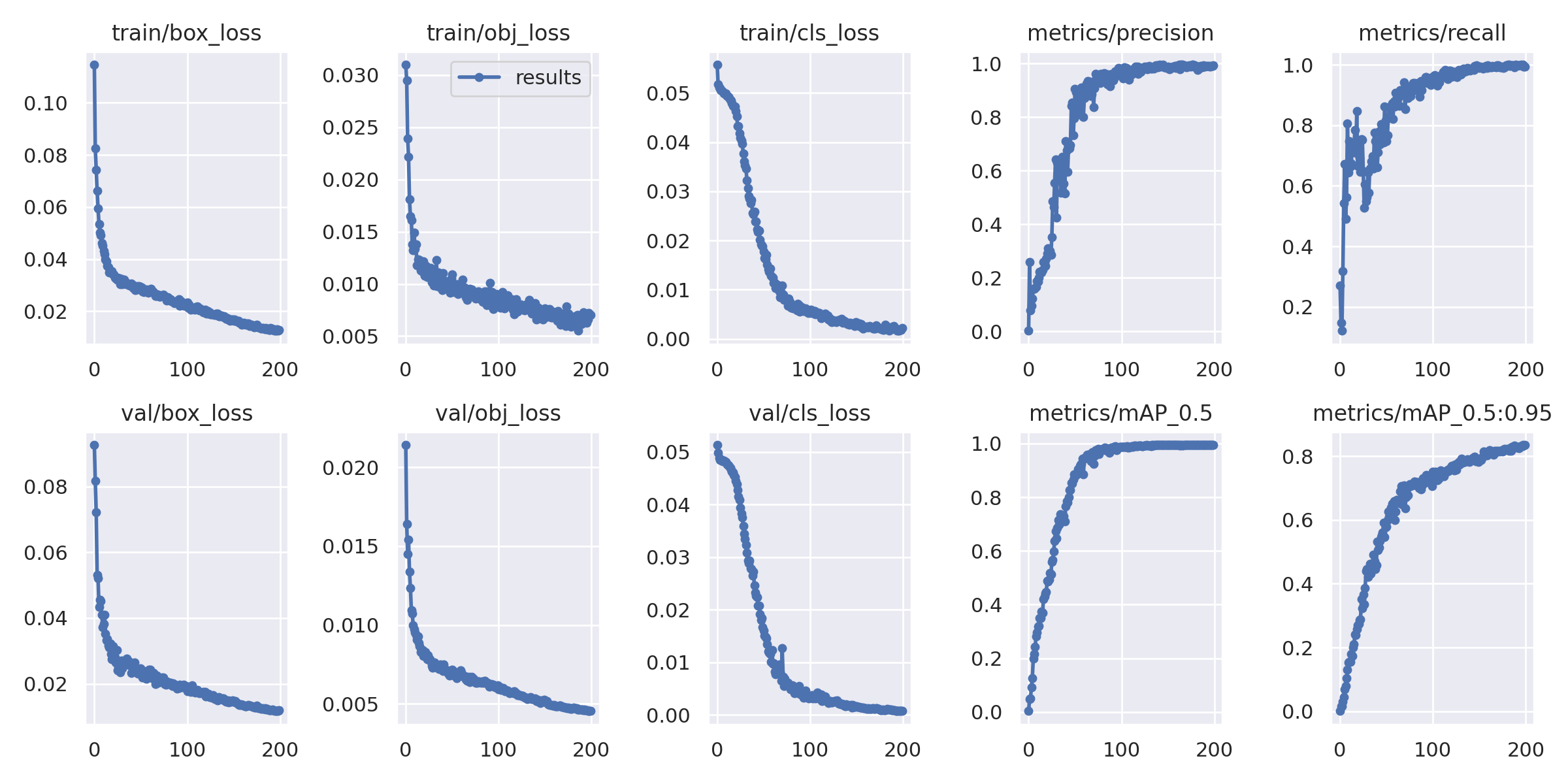


비록 같은 valid batch는 아니지만 오분류가 눈에 띄게 사라졌다.


도움을 받은 문서(한국어)
https://yeko90.tistory.com/entry/ultralytics-yolov5-tutorial
ultralytics yolov5 사용법 완벽 정리
yolov5 모델을 손쉽게 학습(train) 및 추론(inference) 할 수 있는 방법이 뭐가 있을까요? 바로 ultralytics yolov5 를 사용하는 것입니다. 이번 포스팅에서는 ultralytics yolov5 를 통해 학습 및 추론 하는 방법에
yeko90.tistory.com
https://minding-deep-learning.tistory.com/19
[YOLOv5] YOLOv5 Custom Data로 학습시켜보기
YOLOv4를 실습하려다가... 우연히 YOLOv5도 있다는 것을 발견하고 직접 학습시켜보기로 했다! 지금까지 YOLO모델을 직접 학습시켜본 적은 없었기 때문에 좋은 경험이 될 것이라고 생각했다. YOLOv5에
minding-deep-learning.tistory.com
YOLOv5 학습 예제 코드 (튜토리얼) - 마스크 쓰고 있는/안 쓴 얼굴(사람) 찾기
YOLOv5는 x(x-large), l(large), m(medium), s(small)의 4종류로 구성됩니다. 자세한 내용은 이전 글을 참조해주시고, 이 포스트에서는 학습 코드(스크립트)에 대해서 다루고자 합니다. [분류 전체보기] - YOLO v5
lv99.tistory.com
https://bong-sik.tistory.com/30
[Yolo5] Yolo5의 detect.py 사용해서 Yolo 학습용 데이터셋 만들기
우리집엔 봉식이뿐이지만, 고양이가 고양이를 불러서인지 다묘가정이 더 많은 것 같다. 그래서 다묘가정을 위한... 두,세 마리 고양이를 각각 구분하는 모델을 만들어보고자 하는데 저번처럼 또
bong-sik.tistory.com
마지막에 붙인 봉식이누나 님의 티스토리 문서가 특히 많은 도움이 되었다.
봉식이와 봉식이누나 님이 건강하시기를…
'공부 > Data Science' 카테고리의 다른 글
| 부스트코스 코칭스터디 ’인공지능 기초 다지기(AI Basic) 2023’ 지원 (0) | 2022.12.14 |
|---|---|
| <데싸노트의 실전에서 통하는 머신러닝> 북 스포일러 (0) | 2022.08.23 |
| TIL: What is 'data annotation'? (0) | 2022.06.28 |
| 데이터 사이언티스트/데이터 분석가 커리어를 위해서 무엇부터 준비해야 할까? & 필수 기술! (0) | 2022.06.10 |
| 구글 코랩에서 셀레니움을 사용하려는데 잘 되지 않아요 (1) | 2022.06.06 |
- Total
- Today
- Yesterday
- 데이터과학
- 이자포스터디
- 깃허브
- 코테공부
- 데이터준전문가
- 빅데이터
- ADsP
- 자버
- data annotation
- 이력서
- googlecolab
- github
- Notion2Tistory
- 자격증
- 빅분기
- 데이터분석
- 인공지능
- 커리어코칭
- ai부트캠프
- 코드스테이츠
- Kaggle
- 개발자포트폴리오
- 취업준비
- 빅데이터분석기사
- 빅분기후기
- 빅분기합격
- todayIlearned
- Til
- ADsP합격후기
- 데이터준전문가합격후기
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |